

Welcome!
In 2000, the Signal Processing and Speech Communication Laboratory (SPSC Lab) of Graz University of Technology (TU Graz) was founded as a research and education center in nonlinear signal processing and computational intelligence, algorithm engineering, as well as circuits & systems modeling and design. It covers applications in wireless communications, speech/audio communication, and telecommunications.
If you want to learn more about Signal Processing, click: What is Signal Processing?
The Research of SPSC Lab addresses fundamental and applied research problems in five scientific areas:
- Audio and Acoustics
- Intelligent Systems
- Nonlinear Signal Processing
- Speech Communication
- Wireless Communications
Profiles
Result of the Month
Infant Detection using UWB Radar
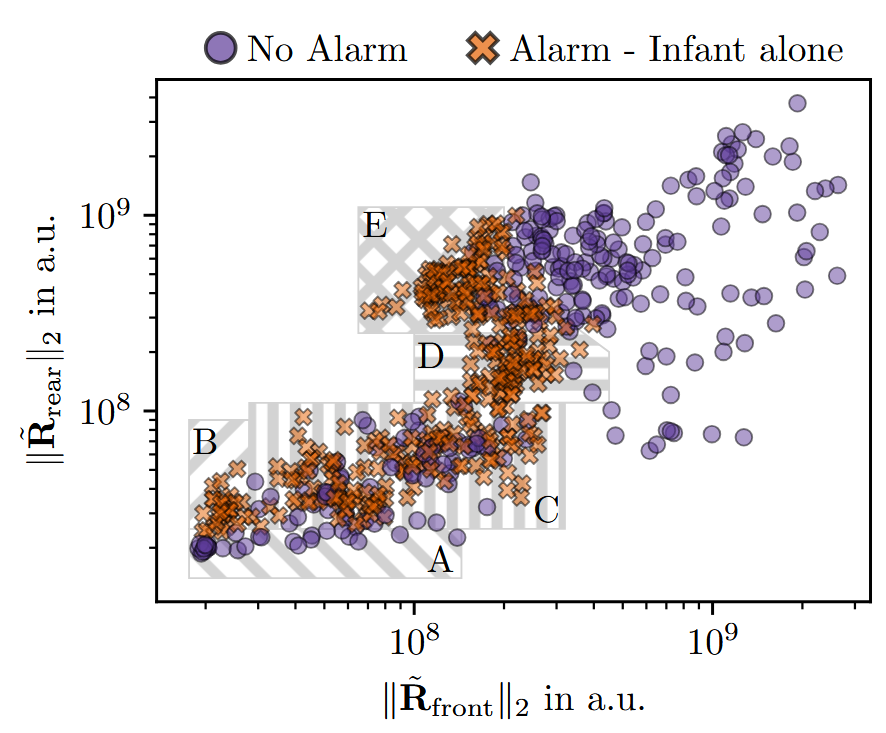
In this study, we explored the use of ultra-wideband radar to detect an unattended infant inside a car. The UWB radar device captures changes in the channel impulse response due to limb movement or chest movement caused by respiration, which can be leveraged to predict the occupancy state of the car. This problem is formulated as a binary classification task, where the goal is to determine whether to raise an alarm when an infant is alone in the car.
Read the full article.Contact: Lukas Klantschnig