
GRASS – Orthographic Transcription and Forced Alignment
This article is part of GRASS: the Graz corpus of Read And Spontaneous Speech.
Transcription Protocol
- PRAAT, separate tiers, short chunks of max. 6s
- hesitations, repetitions and disfluencies
- laughter, breathing, smacking, singing, etc.
- foreign and dialect words
- manner of articulation, e.g., whispered, laughed speech
- overlapping speech
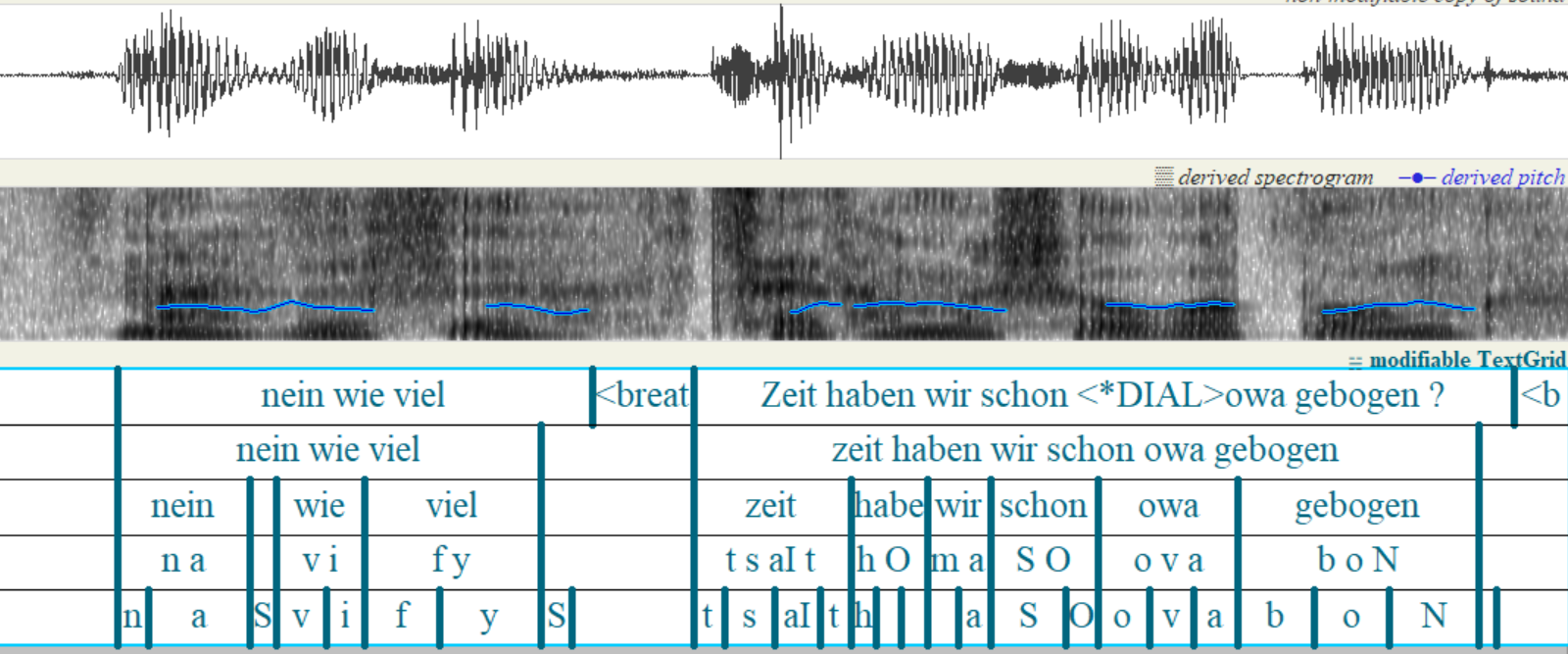
Here you can find a complete set of symbols used for the creation of the orthographic transcriptions.
Transcription Procedure
- 6 transcribers participated training workshop
- Then, they transcribed one conversation
- Second workshop: mutual correction of transcription
- Transcription of other conversations
- Correction by 1 transcriber other than who made the first transcription
During the whole transcription process, the transcribers continued to add content to a transcription protocol and to a lexicon (for the spelling of non-standard words, particles and non-lexical items), which they (online) shared amongst them.
Forced alignments were done with Kaldi, fine-tuned on the corpus data. The alignments are annotated on three levels: the utterance level, the word level, and the phone level (in SAMPA for German).