
What do self-supervised speech representations encode? An analysis of languages, varieties, speaking styles and speakers
- Published
- Fri, Sep 01, 2023
- Tags
- rotm
- Contact
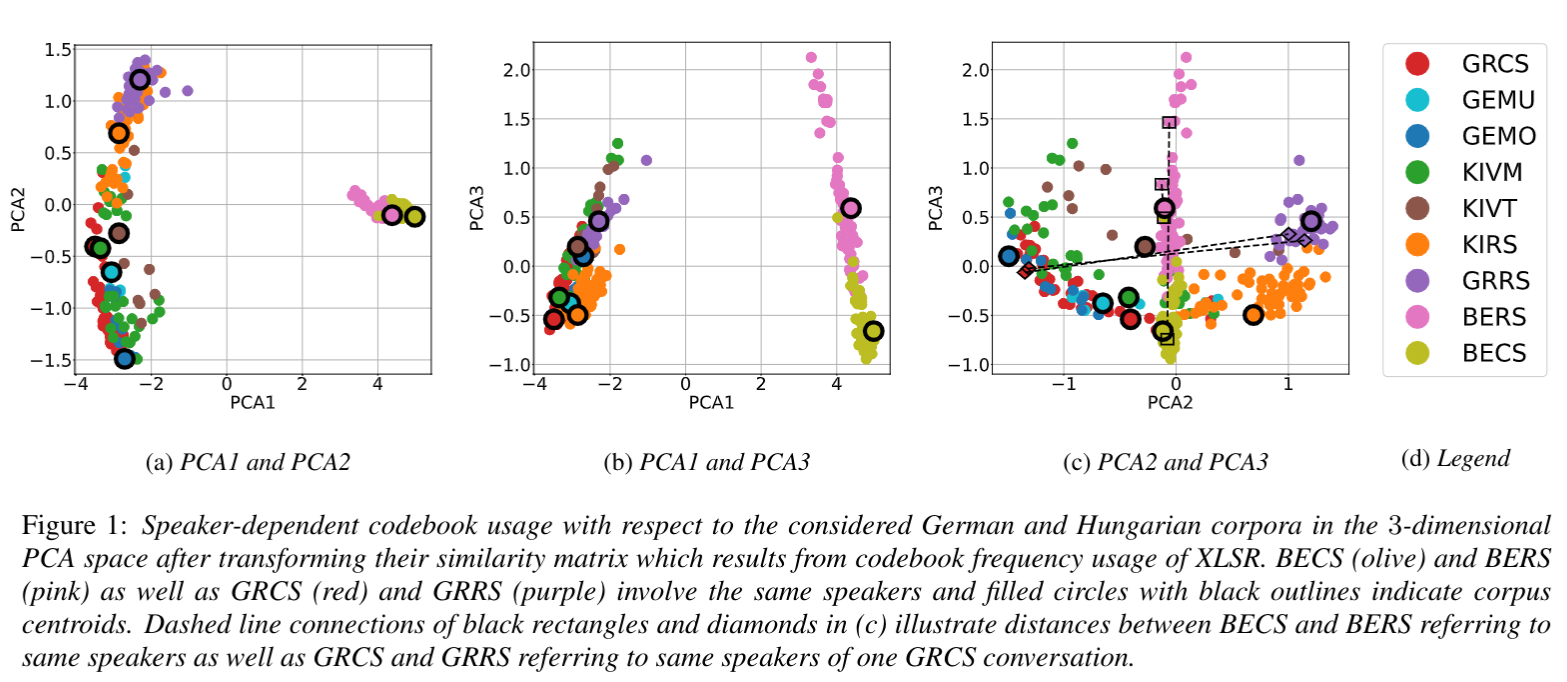
Automatic speech recognition systems based on self-supervised learning yield excellent performance for read, but not so for conversational speech. This work contributes insights into how corpora from different languages and speaking styles are encoded in shared discrete speech representations (based on wav2vec2 XLSR). We analyze codebook entries of data from two languages from different language families (i.e., German and Hungarian), of data from different varieties from the same language (i.e., German and Austrian German) and of data from different speaking styles (read and conversational speech). We find that – as expected – the two languages are clearly separable. With respect to speaking style, conversational Austrian German has the highest similarity with a corpus of similar spontaneity from a different German variety, and speakers differ more among themselves when using different speaking styles than from other speakers of a different region when using the same speaking style.
This work is published at the twenty-fourth edition of Interspeech and will be presented in August 2023.
Browse the Results of the Month archive.