
Data and Modeling Assumptions in Physics-Informed Operator Learning
- Published
- Sat, Nov 01, 2025
- Tags
- rotm
- Contact
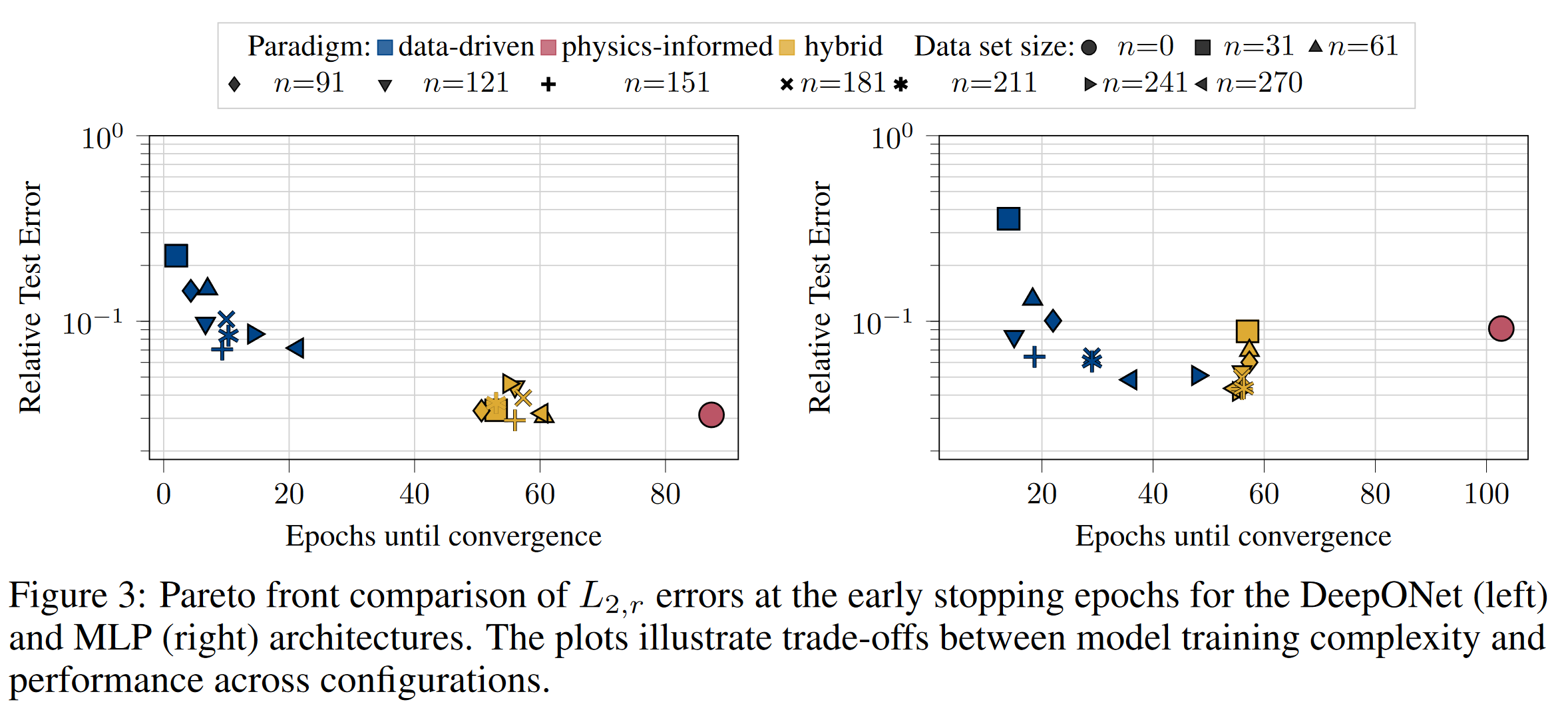
Operator networks have emerged as promising surrogate models, replacing computationally expensive numerical solvers for differential equations. Beyond achieving competitive accuracy with traditional solvers, the practical viability of this approach greatly depends on its training cost, which is comprised of ground truth data acquisition and network optimization. Physics-informed machine learning seeks to reduce reliance on labeled data by embedding the governing differential equations into the loss function; however, such models are often very challenging to train using physics constraints alone.
In this work, we study how varying amounts of labeled data and architectural choices affect convergence and final performance in operator learning. Our results show that incorporating training data into a physics-informed training regime can significantly reduce training time. However, this effect does not scale with the amount of data used. Conversely, adding physics-based residuals can substantially enhance performance, if the network architecture is well-suited to exploit the underlying physical behavior. Architectures specifically designed for operator learning, such as DeepONet, combined with suitable inductive biases, such as Fourier feature embeddings, play a crucial role in leveraging the potential of the physics loss.
This paper was accepted for the 2025 EurIPS workshop on Differentiable Systems and Scientific Machine Learning.
Browse the Results of the Month archive.