
Towards building a cross-lingual speech recognition system for Slovenian and Austrian German
- Published
- Sun, Nov 01, 2020
- Tags
- rotm
- Contact
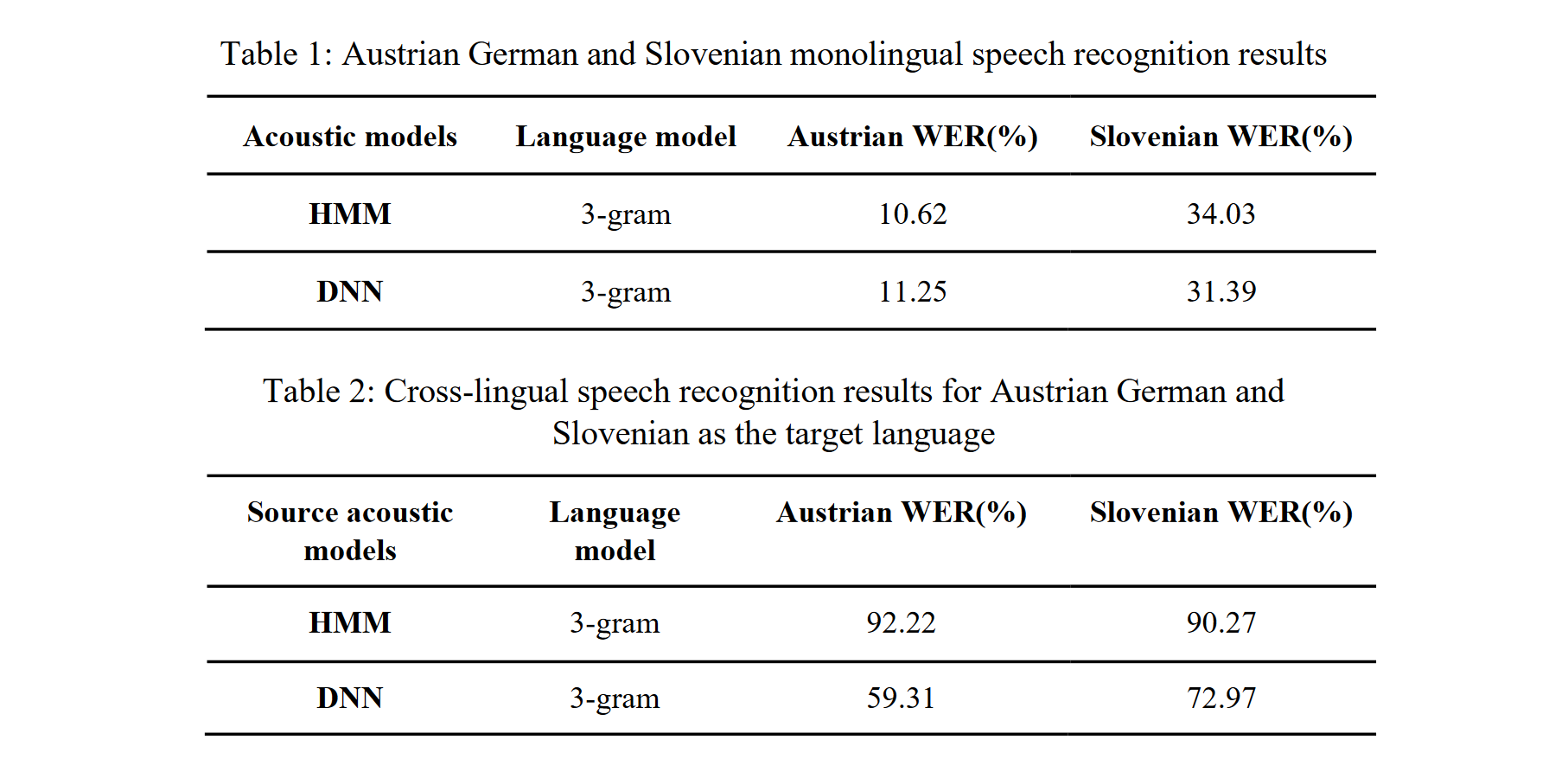
Methods of cross-lingual speech recognition have a high potential to overcome limitations on resources of spoken language in under-resourced languages. Not only can they be applied to build automatic speech recognition (ASR) systems for such languages, they can also be utilized to generate further resources of spoken language. This paper presents a cross-lingual ASR system based on data from two languages, Slovenian and Austrian German. Both were used as a source and target language for cross-lingual transfer (i.e., the acoustic models were trained on material from the source language, and recognition was tested on material from the target language). The cross-lingual mapping between the Slovenian phone set (40 phones) and the Austrian German phone set (33 phones) was carried out using expert knowledge about the acoustic-phonetic properties of the phones. For the experiments, we used data from two speech corpora: the Slovenian BNSI Broadcast News speech database and the Austrian German GRASS corpus. We trained HMM and DNN acoustic models for monolingual and cross-lingual speech recognition. Evaluating the results (Table 1,2), it became clear that the DNN acoustic models outperformed the HMM models. The speech recognition results (Table 2) for Austrian German as the target language clearly outperformed those with Slovenian as the target language. Possible explanations for this difference in performance are: 1) The higher number of phones in the Slovenian language, 2) The speaking style discrepancies of the databases (i.e., a mix of read and spontaneous speech in the Slovenian data vs. read speech only in the Austrian data), and 3) the recording quality mismatch (i.e., GRASS is recorded under better conditions than BNSI). The full version of the paper can be found on The Phonetician.
Browse the Results of the Month archive.