
Bayesian Neural Networks with Weight Sharing Using Dirichlet Processes
- Published
- Wed, May 01, 2019
- Tags
- rotm
- Contact
We extend feed-forward neural networks with a Dirichlet process prior over the weight distribution. This enforces a sharing on the network weights, which can reduce the overall number of parameters drastically. We alternately sample from the posterior of the weights and the posterior of assignments of network connections to the weights. This results in a weight sharing that is adopted to the given data. In order to make the procedure feasible, we present several techniques to reduce the computational burden. Experiments show that our approach mostly outperforms models with random weight sharing. Our model is capable of reducing the memory footprint substantially while maintaining a good performance compared to neural networks without weight sharing.
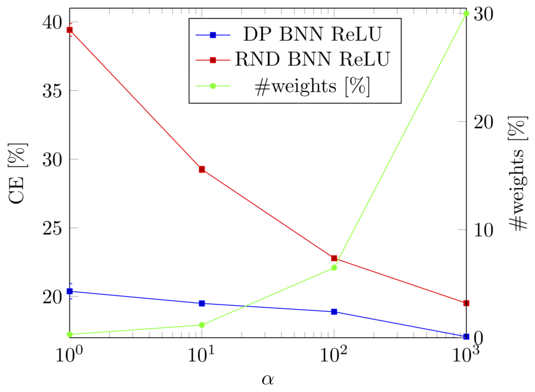
Figure: The concentration parameter alpha of the Dirichlet processes can be used to trade-off between the classification error (CE) and the memory requirements of the model, i.e., how many weights are shared. Especially if only a few weights are used (small alpha), our model (DP BNN ReLU) outperforms neural networks with random weight sharing (RND BNN ReLU) by a large margin.
More information can be found in our paper.
Browse the Results of the Month archive.