
On the use of acoustic features for automatic disambiguation of homophones in spontaneous German
- Published
- Mon, Apr 01, 2019
- Tags
- rotm
- Contact
Homophones pose serious issues for automatic speech recognition (ASR) as they have the same pronunciation but different meanings or spellings. Homophone disambiguation is usually done within a stochastic language model or by an analysis of the homophonous word’s context. Whereas this method reaches good results in read speech, it fails in conversational, spontaneous speech, where utterances are often short, contain disfluencies and/or are realized syntactically incomplete. Phonetic studies have shown that words that are homophonous in read speech often differ in their phonetic detail in spontaneous speech. Whereas humans use phonetic detail to disambiguate homophones, this linguistic information is usually not explicitly incorporated into ASR systems.
In this paper, we show that phonetic detail can be used to automatically disambiguate homophones using the example of German pronouns. In these example sentences, “der” fuctions as article (A) and as relative pronoun (B):
- (A) Hans, der Floh, hatte ein gutes Leben.
- John, the flea, had a good life.
- (B) Hans, der floh, hatte ein gutes Leben.
- John, who fled, had a good life.
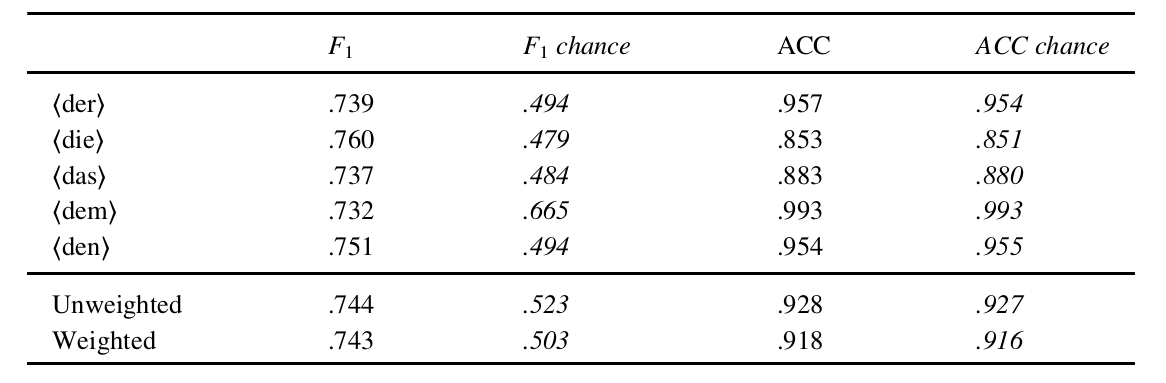
Using 3179 homophonous tokens from a corpus of spontaneous German and a set of acoustic features, we trained a random forest model. Our results show that homophones can be disambiguated reasonably well using acoustic features (74% F1, 92% accuracy). In particular, this model is able to outperform a model based on lexical context (48% F1, 89% accuracy). This paper is of relevance for speech technologists and linguists: amodule using phonetic detail similar to the presented model is suitable to be integrated in ASR systems in order to improve recognition. An approach similar to the work here that combines the automatic extraction of acoustic features with statistical analysis is suitable to be integrated in phonetic analysis aiming at finding out more about the contribution and interplay of acoustic features for functional categories.
Table: Unweighted and weighted averages for all pronoun categories . Chance values are given for reference. These were computed by predicting always the most frequent POS tag.
More information can be found in our paper.
Browse the Results of the Month archive.