
A Simple and Effective Framework for A Priori SNR Estimation
- Published
- Mon, Oct 01, 2018
- Tags
- rotm
- Contact
- DOI
- 10.1109/ICASSP.2018.8461787
In this work, we address the problem of estimating the a priori SNR for single-channel speech enhancement. Similar to the decision-directed (DD) approach we linearly combine the maximum likelihood estimate of the current a priori SNR with an estimate obtained from the previous frame. Based on the harmonic model for voiced speech we propose to smooth the a priori SNR estimate along harmonic trajectories instead of fixed discrete Fourier transform frequency bins. We interpolate from fixed DFT frequencies to harmonic frequencies by using a pitch-adaptive zero-padding in the time domain. The resulting pitch-adaptive decision-directed (PADDi) method increases the noise attenuation compared to the classical decision-directed approach and outperforms benchmark methods in terms of speech enhancement performance for several noise types at different SNRs, quantified by objective evaluation criteria.
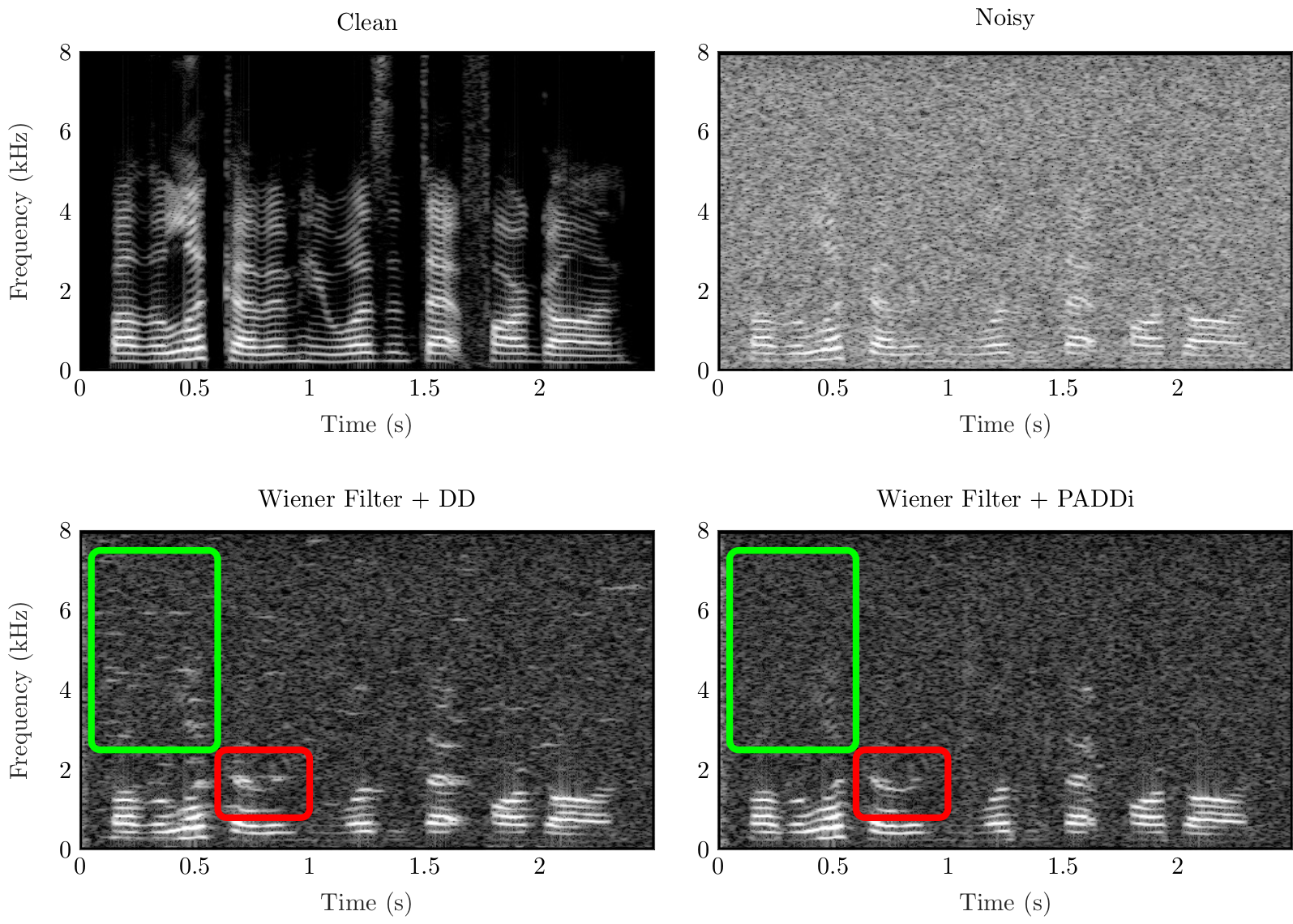
The figure shows spectrograms of clean, noisy, and enhanced speech. The noisy signal is obtained by mixing speech and white noise at 0 dB SNR. The enhanced speech is obtained by applying a Wiener filter, first with a priori SNR estimated by the decisiion-directed (DD) approach and second with PADDi as a priori SNR estimator. The green rectangle emphasizes on time-frequency regions that illustrate that the classical DD approach results in spurious spectral peaks which may be perceived as musical noise while PADDi does not suffer from such artifacts. Further, the red rectangle indicates thatt harmonic fine structure in low-frequency regions is better preserved by PADDi compared to the DD approach.
More information can be found in our paper.
Browse the Results of the Month archive.