
A Pitch-Synchronous Simultaneous Detection-Estimation Framework for Speech Enhancement
- Published
- Thu, Feb 01, 2018
- Tags
- rotm
- Contact
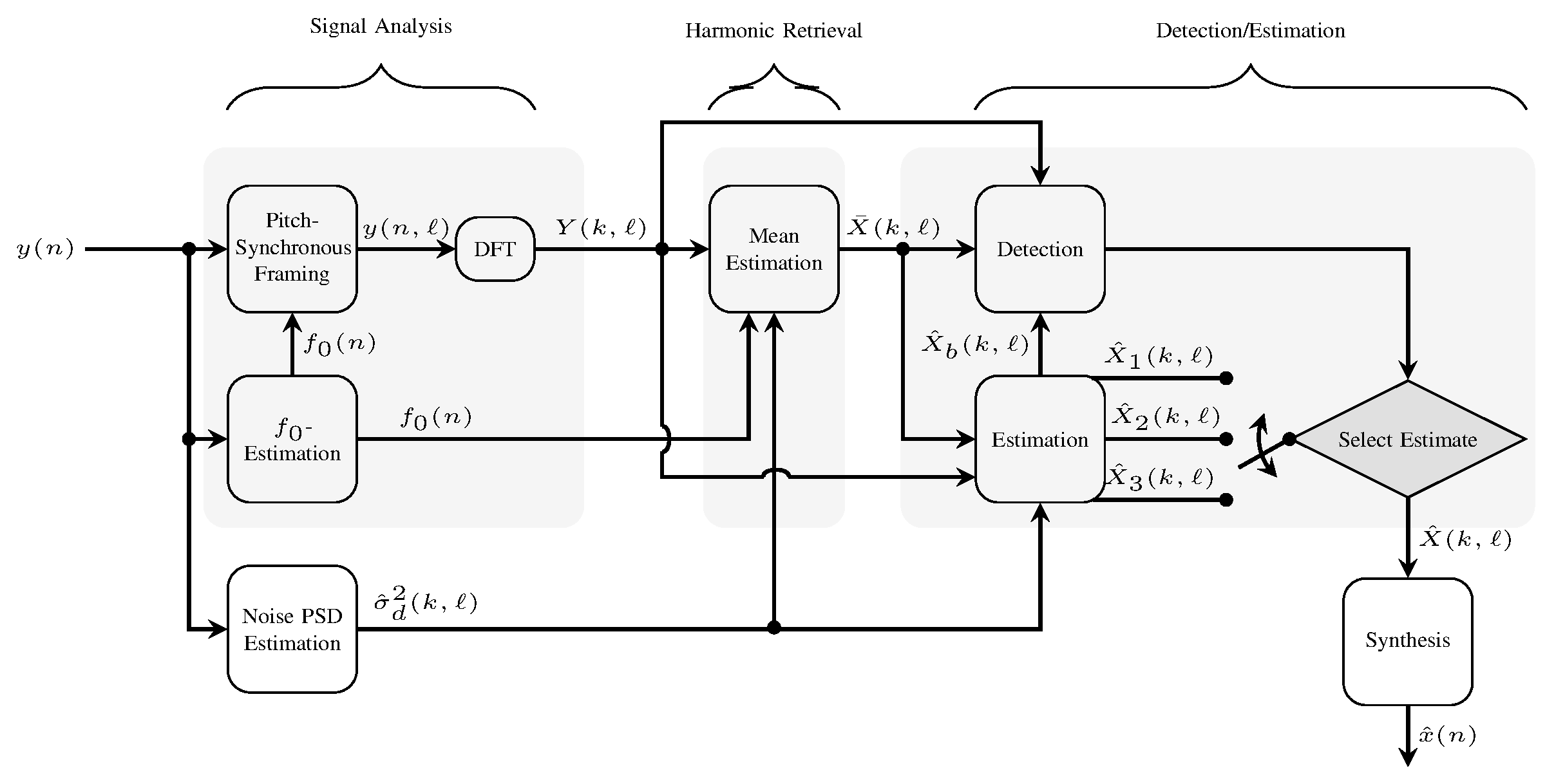
Speech enhancement methods formulated in the STFT domain vary in the statistical assumptions made on the STFT coefficients, in the optimization criteria applied or in the models of the signal components. Recently, approaches relying on a stochastic-deterministic speech model have been proposed. The deterministic part of the signal corresponds to harmonically related sinusoids, often used to represent voiced speech. The stochastic part models signal components that are not captured by the deterministic components. In this work, we consider this scenario under a new perspective yielding three main contributions. First, a pitch-synchronous signal representation is considered and shown to be advantageous for the estimation of the harmonic model parameters. Second, we model the harmonic amplitudes in voiced speech as random variables with frequency bin dependent Gamma distributions. Finally, distinct estimators for the different models of voiced speech, unvoiced speech, and speech absence are derived. To select from the arising estimates, we take into account the mutual impact of detection and estimation by proposing a binary decision framework that is derived from a Bayesian risk function.
The figure shows a block diagram of the proposed estimation scheme. Areas highlighted in gray illustrate separate modules which can in principle be replaced by any other method performing the tasks of signal analysis, harmonic retrieval or detection/estimation.
More information can be found in our paper.
Browse the Results of the Month archive.