
Iterative Harmonic Speech Enhancement
- Published
- Sat, Oct 01, 2016
- Tags
- rotm
- Contact
In digital speech transmission the transmitted speech signal is often corrupted by noise arising from various kinds of sources such as passing cars or chatting people in a restaurant. The aim of speech enhancement is to compensate for the detrimental effects these interferences have on the speech quality. In this work we present a method to enhance voiced speech segments only, which are often modeled as a sum of harmonically related sinusoids. We propose an iterative estimation scheme to jointly estimate the harmonic parameters, i.e., amplitude, frequency and phase of the harmonics of the underlying speech signal. Here we utilize the expectation-maximazation (EM) algorithm to obtain the harmonic parameters which are then used to reconstruct voiced speech segments. The potential of the proposed speech enhancement method in terms of harmonic parameter estimation is validated on synthetic harmonic signals. Further, by applying it to noise corrupted speech files we demonstrate its effectiveness in improving instrumentally predicted speech intelligibility and perceived speech quality.
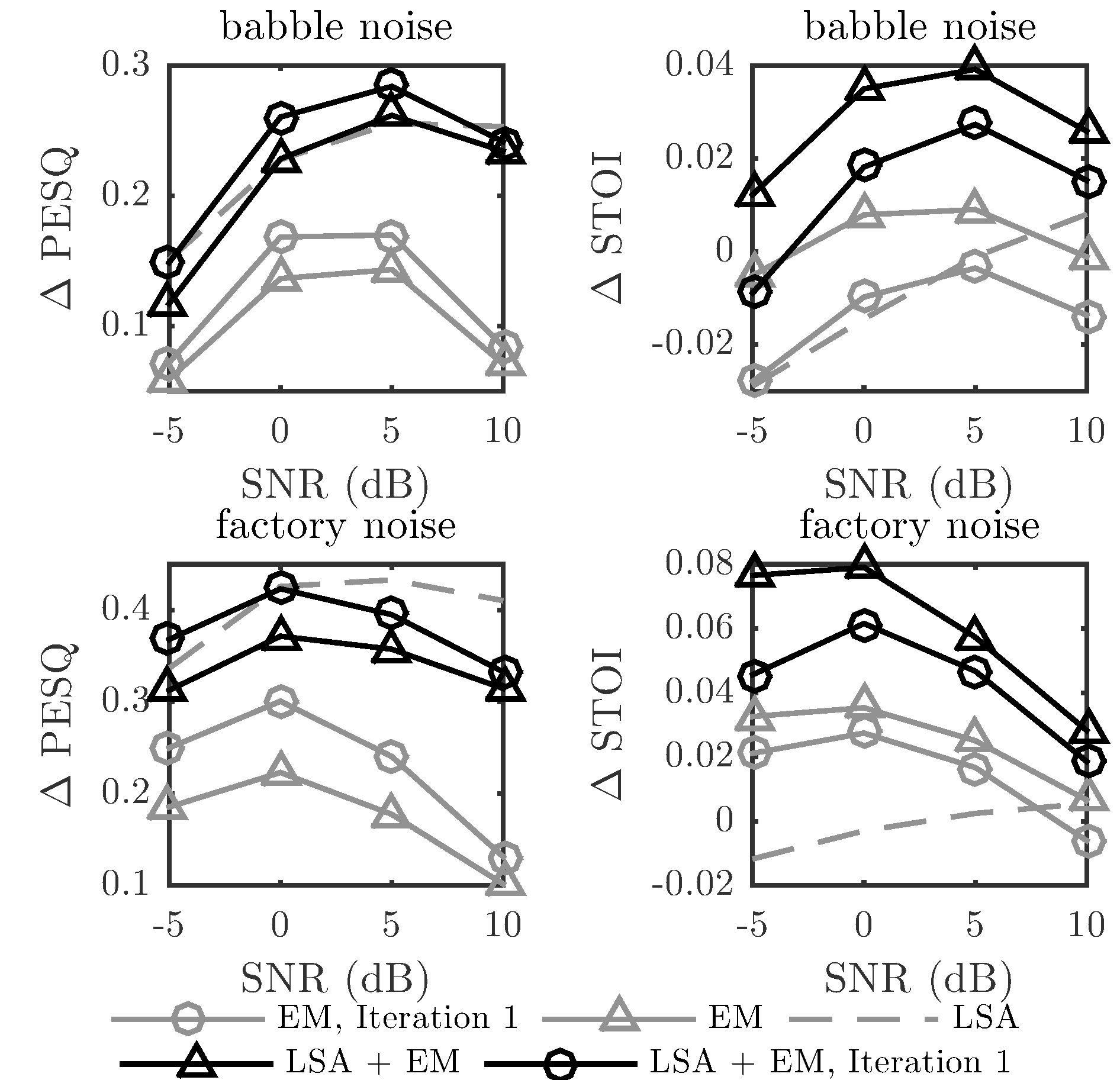
The figure illustrates the performance of the proposed scheme in terms of perceived speech quality and intelligibility, instrumentally predicted by perceptual evaluation of speech quality (PESQ) and short time objective intelligibility (STOI), respectively. We report the improvement compared to the noise corrupted speech signals. Since the harmonic model is only valid for voiced frames, for unvoiced frames we use the log-spectral amplitude (LSA) estimator. The EM algorithm is initialized with the least squares solution for the harmonic parameters, denoted as iteration 1. Especially the intelligibility is improved by refining the harmonic model estimate across iterations. This is an interesting finding since speech enhancement typically improves perceived speech quality but degrades the intelligibility.
More information can be found in our paper.
Browse the Results of the Month archive.