
AMISCO: The Austrian German Multi-Sensor Corpus
- Published
- Wed, Jun 01, 2016
- Tags
- rotm
- Contact
We introduce a unique, comprehensive Austrian German multi-sensor corpus with moving and non-moving speakers to facilitate the evaluation of estimators and detectors that jointly detect a speaker’s spatial and temporal parameters. The corpus is suitable for various machine learning and signal processing tasks, linguistic studies, and studies related to a speaker’s fundamental frequency (due to recorded glottograms). Available corpora are limited to (synthetically generated/spatialized) speech data or recordings of musical instruments that lack moving speakers, glottograms, and/or multi-channel distant speech recordings. That is why we recorded 24 spatially non-moving and moving speakers, balanced male and female, to set up a two-room and 43-channel Austrian German multi-sensor speech corpus. It contains 8.2 hours of read speech based on phonetically balanced sentences, commands, and digits. The orthographic transcriptions include around 53,000 word tokens and 2,070 word types. Special features of this corpus are the laryngograph recordings (representing glottograms required to detect a speaker’s instantaneous fundamental frequency and pitch), corresponding clean-speech recordings, and spatial information and video data provided by four Kinects and a camera.
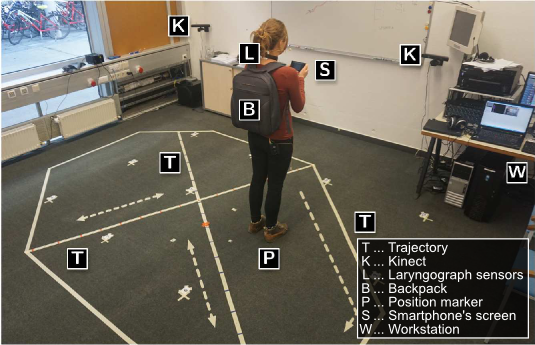
Fig.:A speaker reads sentences shown on the smart-phone’s screen (S) at position ten (P) facing east in our meeting room. There are two Kinects (K) next to the whiteboard, a work station (W) on the right-hand side, and marked trajectories (T) and positions (P) on the floor. The speaker is wearing a back bag (B) containing a battery-driven laryngograph and transmitters. The laryngograph’s sensor (L) is mounted on the speaker’s neck. The bright arrows on the floor mark the directions of movement, the small cross-shaped markers represent the positions with four orientations. The red spot on the left-hand side of the speaker marks the pentagonal array’s center (mounted on the ceiling).
Browse the Results of the Month archive.