
Automatic detection of uncertainty in spontaneous German dialogue
- Published
- Wed, Jul 01, 2015
- Tags
- rotm
- Contact
In this paper, we automatically detected uncertainty in naturalistic spontaneous German human-human conversations. We presented an approach which is based on linguistic, paralinguistic and extralinguistic features. We tested 9 feature classes (timing, fundamental frequency, intensity, spectrum, voice quality, lexicon, syntax, dialogue structure, external features) and evaluated their performance on 1158 dialogue acts taken from the spontaneous part of the Kiel Corpus. The results showed that it is possible to detect uncertainty in speech automatically relatively reliably. The accuracy with which this task is accomplished depended heavily on the feature set employed. In particular, our more complex modelling of speech rate contributed to good classification performance. Automatic feature selection could improve performance even though the machine learning algorithm employed in this paper is built to handle highly correlated features spaces. While only 64 features in size, the resulting feature set outperformed all other feature sets. Even though all features implemented in our system are theoretically motivated and have been used in previous publications, the amount of features that were uninformative regarding the detection of uncertainty in this very speech data is surprisingly large.
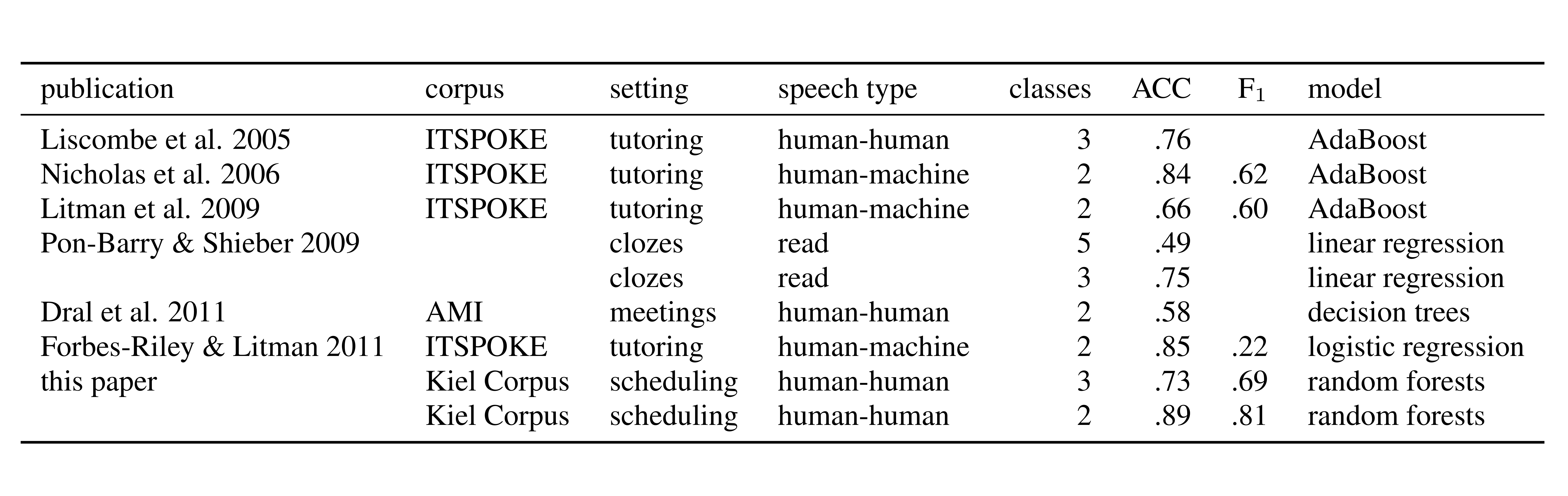
The figure shows a comparison of methods and results as reported in various publications. Reported results are always best results in F1 if available, and accuracy otherwise.
More information can be found in our paper.
Browse the Results of the Month archive.