
Pronunciation variation in Austrian German: A comparison of read and conversational speech
- Published
- Tue, Jul 01, 2014
- Tags
- rotm
- Contact
Whereas for the varieties of German spoken in Germany, conversational speech has been given noticeable attention in the fields of linguistics and automatic speech recognition (ASR), for conversational Austrian there is a lack in speech resources and tools as well as phonetic studies. Based on the recently collected GRASS corpus, we provide rule-based methods for the creation of a pronunciation dictionary and an ASR-supported automatic method for the creation of broad phonetic transcriptions of conversational Austrian German. Our comparative analysis based on these transcriptions showed that whereas only 33.1% of the tokens in read speech show variation from the canonical transcription, this number raises to 63.2% in conversational speech. In the future, we will perform more detailed analysis concerning the conditions for pronunciation variation and incorporate our findings into models of automatic speech recognition.
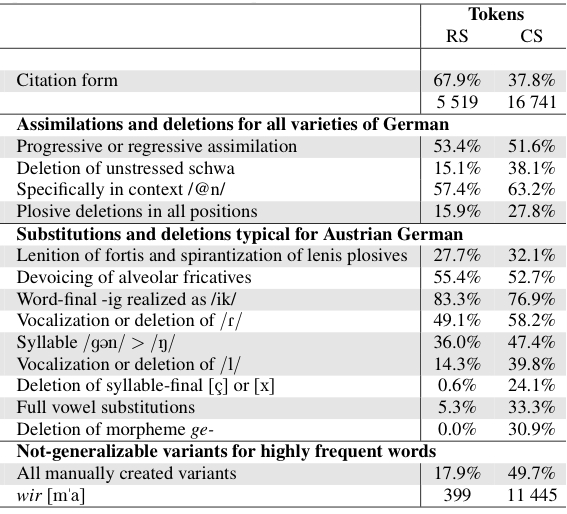
The table shows a summary of our analysis on the frequencies of occurrence of a large number of phonological- and reduction rules in the read speech (RS) component and in the conversational speech (CS) component of the GRASS corpus. For each rule, we show the frequencies in terms of word tokens. For example-words for each of the rules, for the numbers in terms of word types and for the absolute numbers see our Interspeech paper. In general, the rules are devided into three groups: The first group shows those assimilation and reduction rules which can be expected in spontaneous speech in all varieties of German. The second group shows rules which are specific for Austrian German. The third group presents the frequency of pronuniciation variants which were created manually for certain word types and which are not-generalizable.
Browse the Results of the Month archive.