
Bayesian Network Classifiers with Reduced Precision Parameters
- Published
- Thu, Nov 01, 2012
- Tags
- rotm
- Contact
Bayesian network classifers (BNCs) are probabilistic classifers showing good performance in many applications. They consist of a directed acyclic graph and a set of conditional probabilities associated with the nodes of the graph. These conditional probabilities are also referred to as parameters of the BNCs. According to common believe, these classifers are insensitive to deviations of the conditional probabilities under certain conditions. The first condition is that these probabilities are not too extreme, i.e. not too close to 0 or 1. The second is that the posterior over the classes is significantly different. We investigated the effect of precision reduction of the parameters on the classifcation performance of BNCs. The probabilities are either determined generatively or discriminatively. Discriminative probabilities are typically more extreme. However, our results indicate that BNCs with discriminatively optimized parameters are almost as robust to precision reduction as BNCs with generatively optimized parameters. Furthermore, even large precision reduction does not decrease classifcation performance significantly. Our results allow the implementation of BNCs with less computational complexity. This supports application in embedded systems using oating-point numbers with small bit-width. Reduced bit-widths further enable to represent BNCs in the integer domain while maintaining the classification performance.
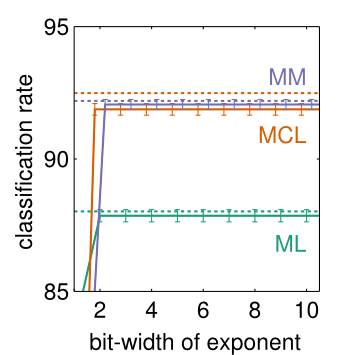
In the figure, the classification rates of BNCs with reduced precision parameters are shown. The data used for classification is taken from the TIMIT speech corpus and a naive Bayes structure is assumed for the BNCs. The classification rates for maximum likelihood (ML), maximum conditional likelihood (MCL) and maximum margin (MM) parameters (in double precision representation) are indicated by the horizontal dotted lines, while classification rates using reduced precision parameters (the mantissa is represented using only 1 bit) together with 95 % confidence intervals are depicted by the solid lines.
Details on our experiments can be found in our paper available at
http://www.cs.bris.ac.uk/~flach/ECMLPKDD2012papers/1125522.pdf
Browse the Results of the Month archive.