
PhD Theses
Prosody has many functions in speech; e.g., cueing information structure (“Max bought a HOUSE.” vs. “MAX bought a house.”), sentence type (“Max bought a house?”), or communicative functions such as turn management (do I want to continue telling you about Max’s new house or am I done talking). This thesis investigates the prosody of yet another kind of communicative function, the expression of attitude (also called stance-taking, evaluation).
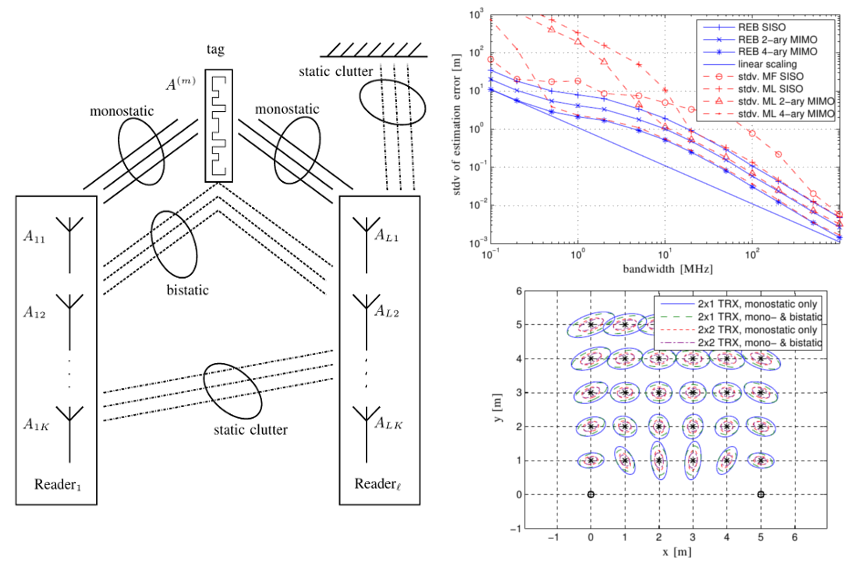
It is hypothesized that the use of cognitive system concepts as well as multiple input, multiple output techniques can enable accurate and robust indoor localization using a passive radio frequency identification (RFID) system.
State-of-the-art ASR systems perform well on read and conversational speech (see modern virtual assistants like Alexa or Siri) but yet the recognition of spontaneous speech is associated with many difficulties which potentially could benefit from new ideas for the speech recognition task. This thesis presents speech recognition experiments which incorporate prosodic information to improve ASR systems for read and - spontaneous - conversational speech. Specifically, this approach is suitable for languages with lower available resources. One of the main reasons for the arising difficulties are the many pronunciation variants which need to be understood and learned when developing modern ASR systems. On this account the main focus lies on the improvement of the acoustic model (which represents one main part of a modern ASR system) by integrating, for example, different long-term and short-term acoustic features. Consequently, the trade-off between knowledge-based and data-driven approaches is levered out by illustrating - and contrasting - the advantages of prosodic information included in the modeling process of ASR systems.
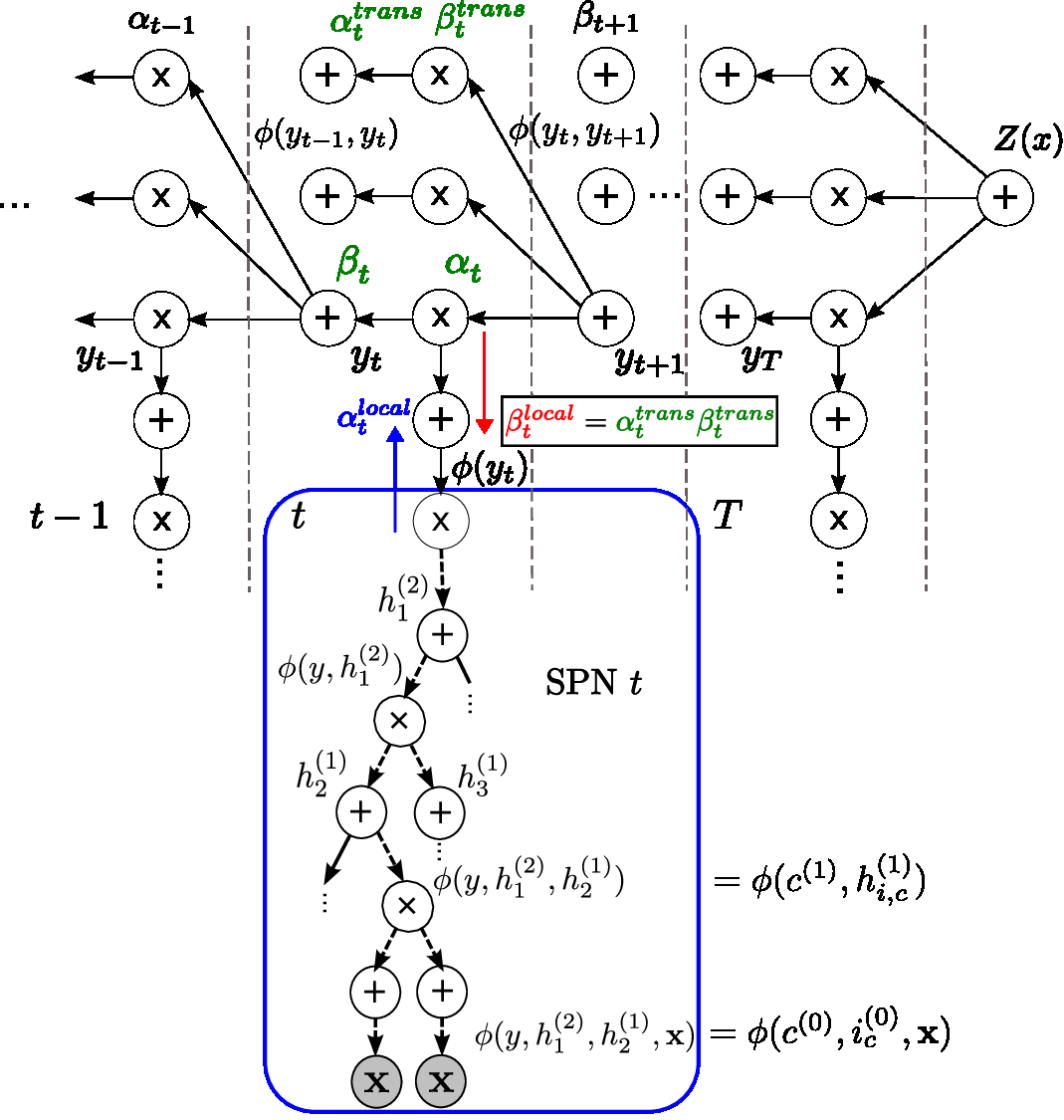
Linear-chain conditional random fields (LC-CRFs) have been successfully applied in many structured prediction tasks. LC-CRFs can be extended by different types of deep models.
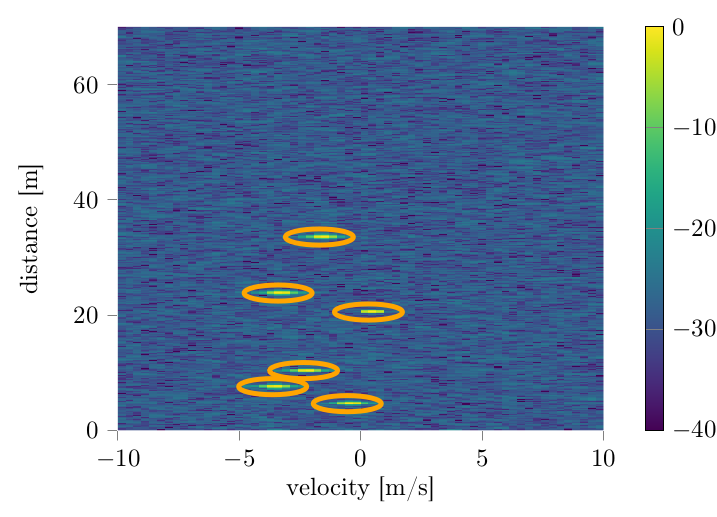
Radar systems provide information about object distances, velocities and positions but they can also be used for object recognition, such as pedestrian classification. The constant sensing of the various sensors in a car produces a huge amount of raw data, which requires an intelligent extraction of relevant data as well as distributed processing on the sensing units themselves. In this project we investigate the use of machine learning methods such as Deep Neural Networks to address these issues. Special attention is placed on resource efficiency of the used models in order to deploy them directly to the hardware.
Radio Frequency (RF) breakdowns are one of the most prevalent limits in RF cavities for particle accelerators. During a breakdown, field enhancement associated with small deformations on the cavity surface results in electrical arcs. Such arcs lead to beam aborts and if they occur frequently, they can cause irreparable damages on the RF cavity surface.
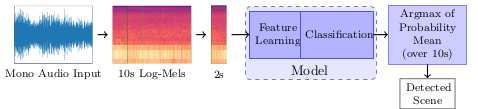
Acoustic scene classification is an important task of a machine hearing system used for classification of general sounds in everyday environments. It aims to characterize and label the acoustic environment of an audio recording. While respiratory sounds classification is a key task on computer-aided lung sound research to support medical diagnosis. It focuses on automatic recognition of respiratory adventitious sounds or healthy and several categories of pathological lung sounds. The thesis develops machine learning methods for these application tasks.
Edge absorbers are known for their high effectiveness in absorbing low-frequency sound energy. Particular attention must be paid to low-frequency sound energy and especially low-frequency reverberation when planning and/or renovating communication rooms, as these have a sensitive effect on speech intelligibility due to masking effects. Here, edge absorbers, commonly known as bass traps, can be used as a subtle and relatively inexpensive acoustic treatment. Although the influence of edge absorbers on the sound field and its decay behaviour has been extensively proven empirically, no suitable modelling of the edge absorber exists to date. For this reason, edge absorbers are hardly ever used in room acoustic simulations.
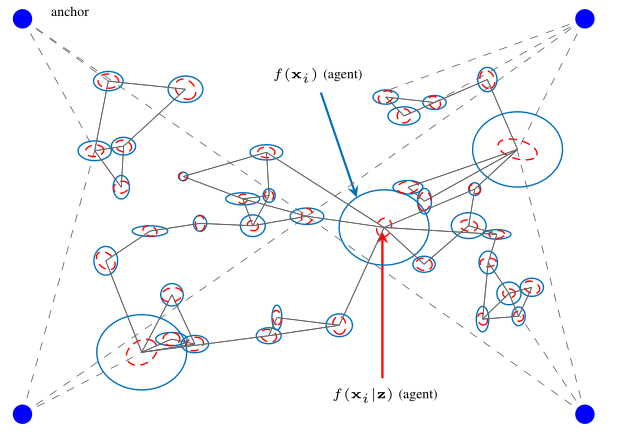
Narrowband positioning of sensors in an indoor environment is highly inaccurate. This problem can be tackeld by using large sensor networks and exploiting massive cooperation and information about the environment.
State-of-the-art automatic speech recognition (ASR) systems achieve accuracies close to human capabilities for read speech. When it comes to conversational speech (CS), systems perform much worse. Reasons for that are, on the one hand, incomplete sentences, wrong grammar, slang vocabulary and a broad pronunciation variation resulting from both linguistic phenomena such as reduced pronunciation in a familiar context and dialect speaking styles. On the other hand, there is usually not enough data available to train existing systems sufficiently. Making use of linguistic knowledge about CS, such as prosodic features, shall generate a better understanding of how the conversational character of a dialogue affects pronunciation and how sentences are grammatically deformed in CS. With the focus on language models (LMs), this understanding is expected to improve current ASR systems for CS without the need of large data bases. The aim of this research is to find prosodic features that contribute to the performance of both ASR systems and human speech perception. Therefore, humans shall challenge the adapted LM(s) in perception experiments yielding further knowledge on to date human superiority in speech recognition of CS which can then again be exploited in ASR and vice versa.
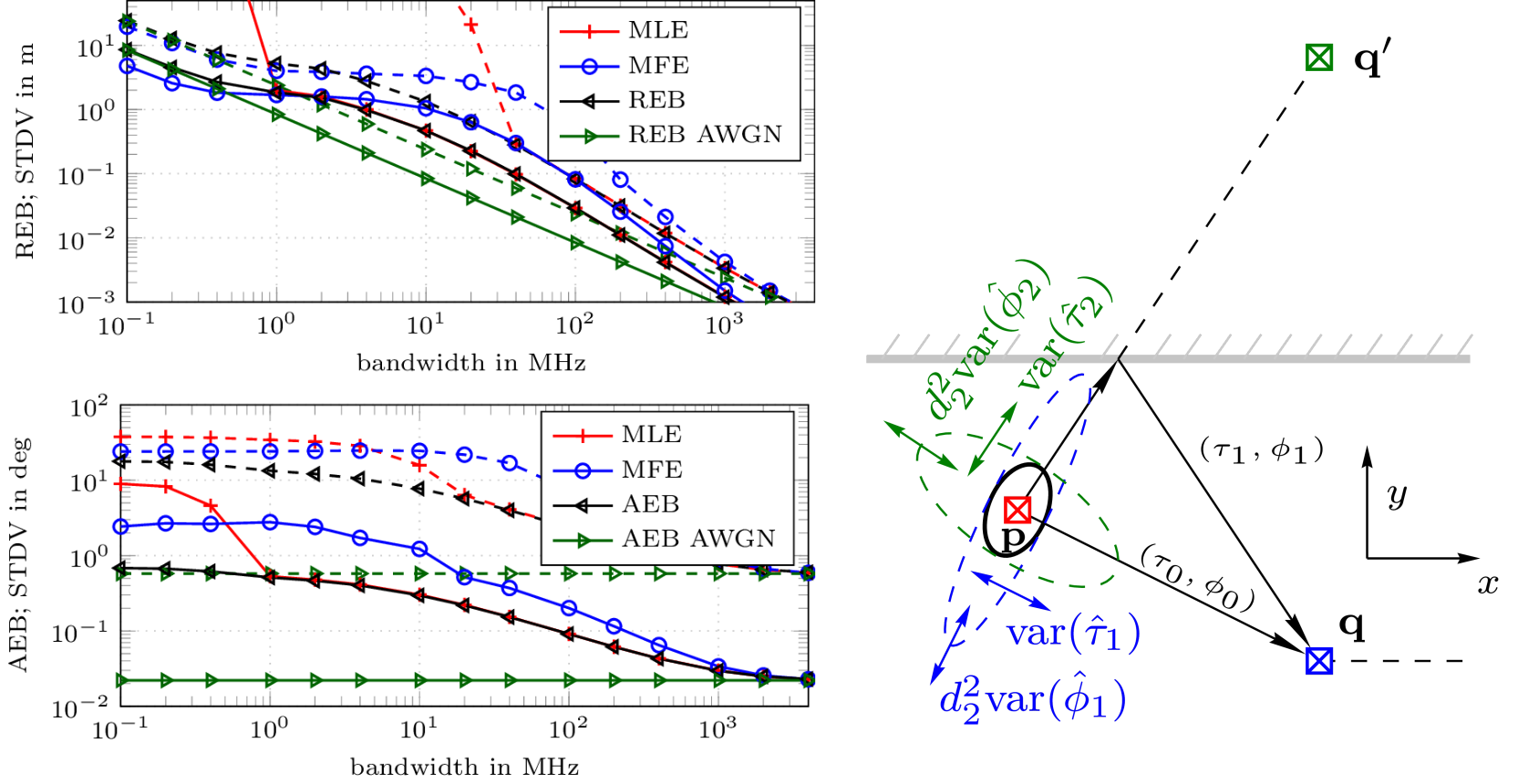
The positioning accuracy that can be achieved using communication over a wireless link between transceivers is envisioned to be improved by the introduction of multiple antenna elements at the RF-devices.
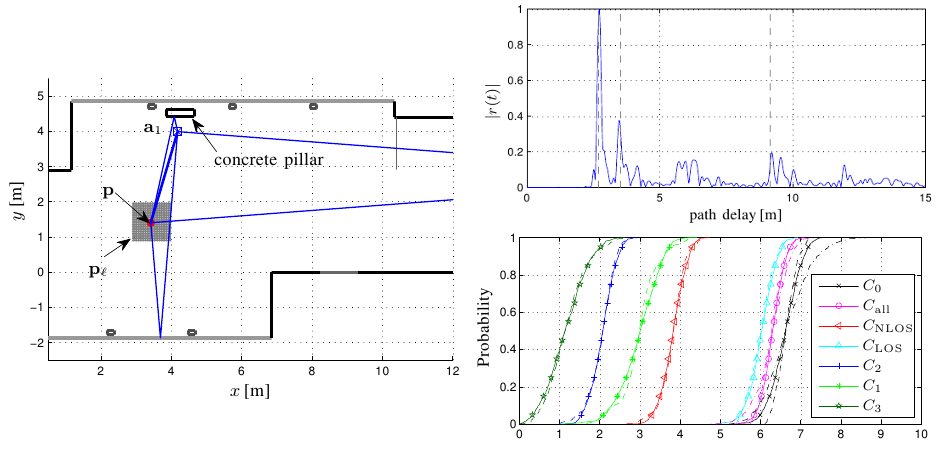
In the upcoming years we face the reality of everyday objects being connected to a large network, the ‘Internet of Things’ (IoT). A key aspect of the IoT is dependable communication and localization, where the participants act as ‘Smart Things’, communicating with each other and being aware of their environment.
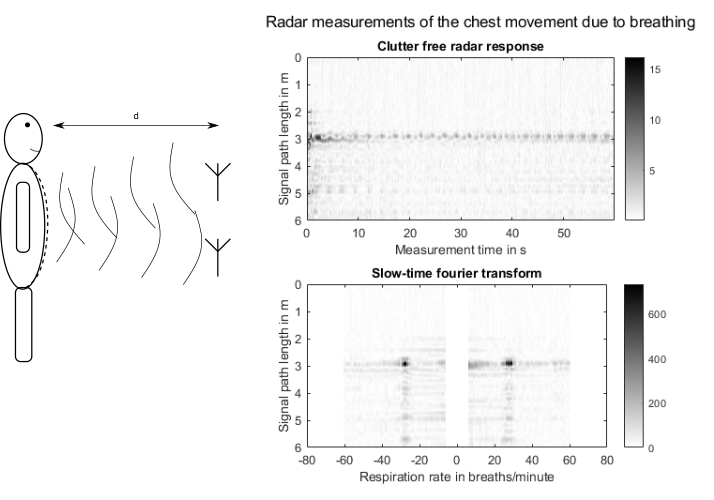
Approximatley 40 tragic deaths of small children locked in vehicles occur in the US each year due to the extreme heat or cold inside the parked vehicle. If the vehicle is able to detect the presence of a child (or any other life such e.g. a pet) it can either alert the owner or adjust the climate control in order to avoid these tragic accidents.
Finished Theses
- A Holistic Approach to Multi-channel Lung Sound Classification — Elmar Messner
- Adaptive Calibration of Frequency Response MIsmatches in Time-Interleaved Analog-to-Digital Converters — Shahzad Saleem
- Adaptive Digital Predistortion of Nonlinear Systems — N.N.
- Sum-Product Networks for Complex Modelling Scenarios — Martin Trapp
- Auditory Inspired Methods for Multiple Speaker Localization and Tracking Using a Circular Microphone Array — Tania Habib
- Behavioral Modeling and Digital Predistortion of Radio Frequency Power Amplifiers — Harald Enzinger
- Cognitive Indoor Positioning and Tracking using Multipath Channel Information — Erik Leitinger
- Complex Baseband Modeling and Digital Predistortion for Wideband RF Power Amplifiers — N.N.
- Digital Enhancement and Multirate Processing Methods for Nonlinear Mixed Signal Systems — N.N.
- Diplophonic Voice: Definitions, models, and detection — Philipp Aichinger
- Distributed Sparse Bayesian Regression in Wireless Sensor Networks — Thomas Buchgraber
- Efficient Floating-Point Implementation of Speech Processing Algorithms on Reconfigurable Hardware — Thang Huynh Viet
- Enhancement for Disordered and Substitution Voices — Martin Hagmüller
- Speech Enhancement Using Deep Neural Beamformers — Matthias Zöhrer
- Improving automatic speech recognition for pluricentric languages exemplified on varieties of German — N.N.
- Indoor localization using RF channel information — Josef Kulmer
- Information Theory for Signal Processing — Bernhard Geiger
- Kernel PCA and Pre-Image Iterations for Speech Enhancemen — Christina Leitner
- Localization, Characterization, and Tracking of Harmonic Sources: With Applications to Speech Signal Processing — Hannes Pessentheiner
- Low Complexity Correction Structures for Time-Varying Systems — Michael Soudan
- Low-Complexity Localization using Standard-Compliant UWB Signals — N.N.
- Low Complexity Ultra-wideband (UWB) Communication Systems in Presence of Multiple-Access Interference — N.N.
- Maximum Margin Bayesian Networks — Sebastian Tschiatschek
- Measurement Methods for Estimating the Error Vector Magnitude in OFDM Transceivers — Karl Freiberger
- Modeling and Mitigation of Narrowband Interference for Non-Coherent UWB Systems — N.N.
- Modeling, Identification, and Compensation of Channel Mismatch Errors in Time-Interleaved Analog-to-Digital Converters — Christian Vogel
- Multipath-Assisted Indoor Positioning — Paul Meissner
- Multipath Tracking and Prediction for Multiple-Input Multiple-Output Wireless Channels — Daniel Arnitz
- Nonlinear System Identification for Mixed Signal Processing — N.N.
- Understanding the Behavior of Belief Propagation — Christian Knoll
- Phonetic Similarity Matching of Non-Literal Transcripts in Automatic Speech Recognition — Stefan Petrik
- Position Aware RFID Systems — Daniel Arnitz
- Probabilistic Methods for Resource Efficiency in Machine Learning — Wolfgang Roth
- Probabilistic Model-Based Multiple Pitch Tracking of Speech — Michael Wohlmayr
- Quality Aspects of Packet-Based Interactive Speech Communication — N.N.
- Reliable and Robust Localization and Positioning — Alexander Venus
- Semantic Similarity in Automatic Speech Recognition for Meetings — N.N.
- Signal Processing for Burst‐Mode RF Transmitter Architectures — Katharina Hausmair
- Signal Processing for Ultra Wideband Transceivers — N.N.
- Signal Processing in Phase-Domain All-Digital Phase-Locked Loops — N.N.
- Source-Filter Model Based Single Channel Speech Separation — Michael Stark
- Sparse Pulsed Auditory Representations For Speech and Audio Coding — Christian Feldbauer
- Speech Enhancement for Disordered and Substitution Voices — Martin Hagmüller
- Speech Enhancement of Electro-Larynx Speech — Anna Katharina Fuchs
- Speech Watermarking and Air Traffic Control — N.N.
- Statistical Signal Processing of Complex-Valued Data for Speech Processing — Johannes Stahl
- Evaluating the decay of sound — Jamilla Balint
- UWB Channel Fading Statistics and Transmitted Reference Communication — N.N.
- Variable Delay Speech Communication over Packet-Switched Networks — N.N.
- Wavelet Analysis For Robust Speech Processing and Applications — N.N.